Integration
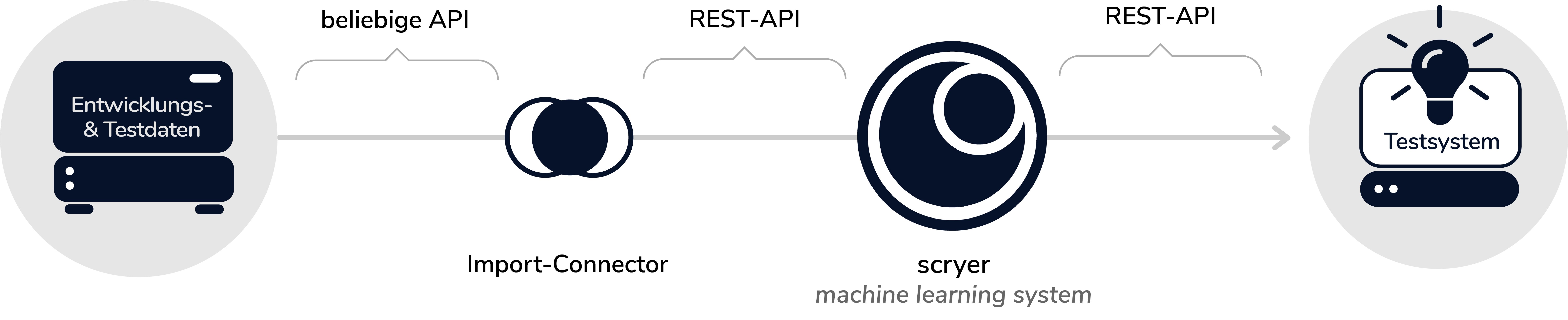
scryer wird an Ihre Testsysteme via Connectoren und REST-APIs angebunden. Hierbei kann scryer lokal oder in einer Cloud integriert werden. Daher ist scryer vollkommen unabhängig von Ihrem Technologie-Stack bzw. den im Testing genutzten Systemen einsetzbar.
Ablauf der Einführung
Wir begleiten Sie in 4 Schritten
1. Initiierungs-Workshop
Im Workshop betrachten wir mit Ihren Ansprechpartnern Ihren Softwareentwicklungsprozess bzw. Ihre Arbeitsweise, vorhandene Verknüpfungen zwischen Tools, Datenbanken, die vorhandenen Datensätze.
Für diesen Status Quo halten wir alle technischen Anforderungen fest, die zur Implementierung scryers notwendig sind und definieren entsprechend die nächsten Schritte.
2. Integration
Je nachdem wie scryer eingebunden werden soll, wird die passende ETL-Strecke gemappt und umgesetzt. Die technische Anbindung scryers können Sie gänzlich selbst oder mit unserer Unterstützung durchführen.
3. Training
scryer wird anhand der zur Verfügung gestellten Daten trainiert. Je nach Datenmenge kann dies ein bis drei Monate dauern. Das Training findet automatisiert statt und ist damit reine Rechenzeit, die von uns überwacht wird.
4. Auswertung
Nach dem Training evaluieren unsere Data Scientisten die Qualität und Aussagekraft der erbrachten Werte. Einerseits werden die Ergebnisse an Ihrem Use Case gemessen. Andererseits ist diese Betrachtung so differenziert, dass sich weitere, neue bedeutende Use Cases ergeben können.
Abschließend präsentieren wir Ihnen unsere Ergebnisse und scryer kann fortan in Ihrem Softwareentwicklungsprozess eingesetzt werden.
Technische Details
Nutzen Sie auch unser FAQ. Hier finden Sie Antworten zu den typischen Fragen, mit denen Kunden auf uns zukommen.
Datenimport
Für den Daten-Import in das scryer-System steht eine REST-API zur Verfügung. Vorhersagen zu Software-Tests und deren Ergebnis können ebenfalls per REST-API abgefragt werden. Eine Beschreibung der REST-API können Sie bei uns direkt anfordern.
Updates
Das Update der Vorhersage-Modelle erfolgt im laufenden Betrieb, dafür werden lediglich neu angefallene Source-Control- und Testdaten eingespielt.
Benötigte Daten
Die notwendigen Daten zum Training von scryer werden aus Source-Control- und Test-Management-Systemen exportiert; z. B. git, TFS (bzw. Azure DevOps Server), IBM Engineering Lifecycle Management (ELM) oder anderen ALM-Systemen. scryer benötigt nur Metadaten, es muss kein Source Code importiert werden.
Installation
scryer kann entweder als On-Site-Installation oder als Cloud-Lösung zur Verfügung gestellt werden.
Technische Voraussetzungen
- 20 bis 60 cores
- 50-100 GB RAM
- 1 - 2 TB Speicherplatz
Haben Sie Fragen zur Integration oder benötigen mehr Informationen?
Wir zeigen Ihnen gerne, wie Sie scryer in Ihre Projekte integrieren können.